数据聚合
数据聚合概述
当我们使用VChart等图表库来绘制柱状图、折线图等图表时,如果使用的数据集dataset并未经过聚合处理,可能会对可视化效果产生不良影响。 举例来说,假设我们有一份商品销售额明细数据集:
// 商品销售数据集
[
{
"Product name": "Coke",
"Sales": 2350
},
{
"Product name": "Coke",
"Sales": 1027
},
{
"Product name": "Coke",
"Sales": 1027
},
{
"Product name": "Coke",
"Sales": 1027
},
{
"Product name": "Sprite",
"Sales": 215
},
{
"Product name": "Sprite",
"Sales": 654
},
{
"Product name": "Sprite",
"Sales": 159
},
{
"Product name": "Sprite",
"Sales": 28
},
{
"Product name": "Fanta",
"Sales": 345
},
{
"Product name": "Fanta",
"Sales": 654
},
{
"Product name": "Fanta",
"Sales": 2100
},
{
"Product name": "Fanta",
"Sales": 1679
},
{
"Product name": "Mirinda",
"Sales": 1476
},
{
"Product name": "Mirinda",
"Sales": 830
},
{
"Product name": "Mirinda",
"Sales": 532
},
{
"Product name": "Mirinda",
"Sales": 498
}
]
在这个数据集中,有两个字段Product name和Sales。可以看出在这个数据集中,有多条数据具有相同的Product name。如果我们想使用这份数据将Product name作为X轴,Sales作为Y轴来绘制柱状图,展示不同地区的销售额,则在X轴每个维值下面将有多条柱子与之对应。
对于这种数据集,不同图表库的处理方式不同。VChart的处理方式是将这些柱子堆叠起来进行展示:
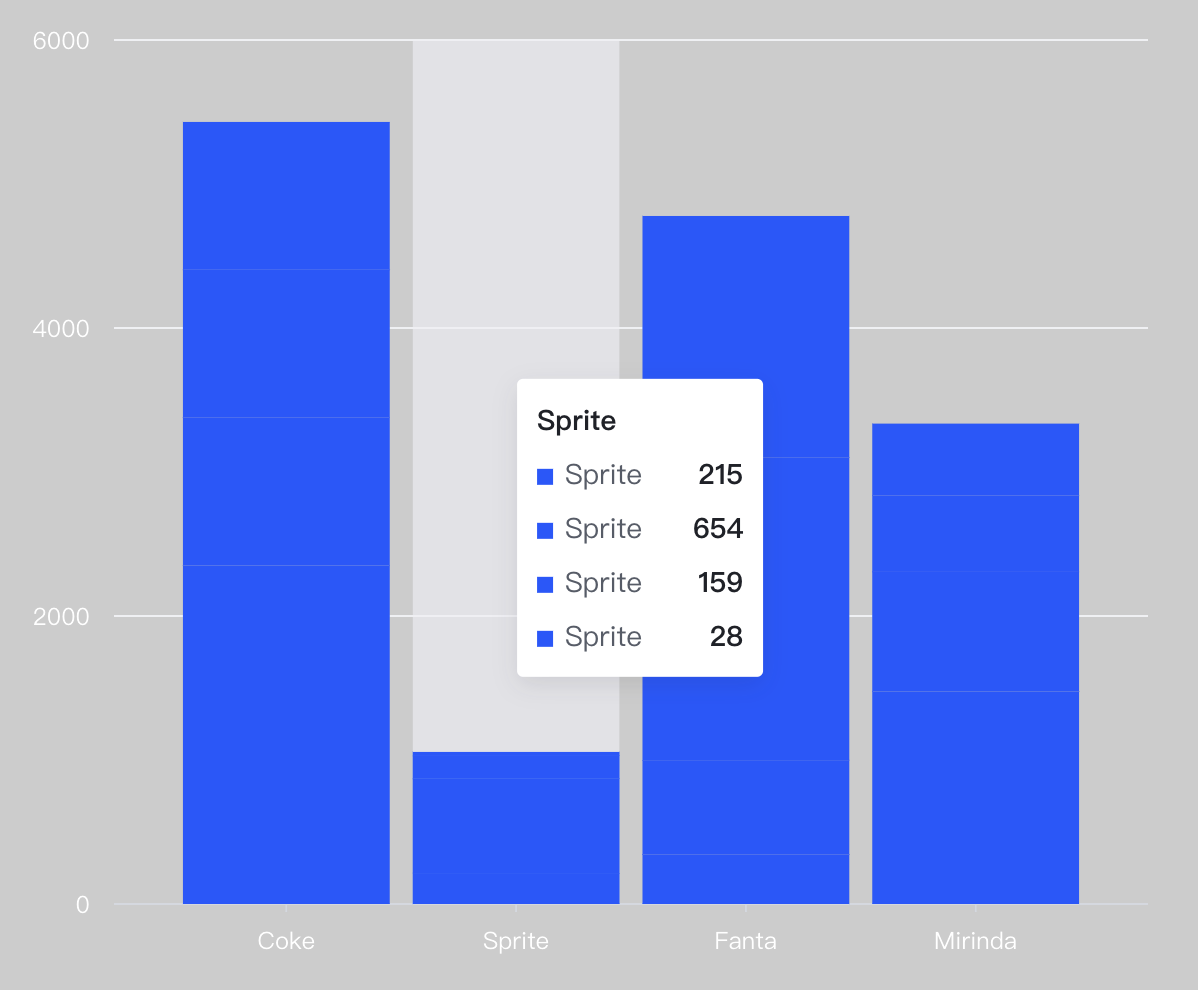
使用这种未聚合的数据集绘制图表可能会有以下几个问题:
- 数据过载:如果数据集非常大,那么图表中可能会有大量的图元,这可能会使图表变得非常混乱,难以阅读和理解,还会导致性能问题。
- 隐藏重要的信息:如果数据没有经过适��当的聚合,那么可能会隐藏一些重要的信息。例如,如果你有一个包含每天销售额的数据集,那么直接绘制这个数据集可能会导致图表变得非常混乱。但是,如果你将数据按月聚合,那么可能会更容易看出销售额的趋势。
- 数据分布不清:未聚合的数据可能会使得数据的分布特征不明显,例如平均值、中位数、众数等。
因此,通常在绘制图表之前,我们会先对数据进行适当的聚合,以便更好地展示数据的特征和趋势。
同时由于原始的数据集没有对字段进行筛选和排序,某些图表展示意图无法满足,例如:帮我展示销售额最多的10个部门,帮我展示北方区域各商品的销售额等。
VMind 1.2.2版本开始支持智能数据聚合功能。该功能会将用户传入的数据作为一张数据表,使用大语言模型根据用户的指令生成SQL查询语句,从数据表中查询数据,并通过GROUP BY和聚合函数对数据进行分组聚合、排序、筛选。
接下来,我们将详细介绍VMind数据聚合功能的使用方法。
dataQuery
VMind对象的dataQuery函数是一个强大的数据聚合工具。它接收三个参数:用户展示意图userPrompt,数据集字段信息fieldInfo和原始数据集dataset。你可以在数据格式与数据处理中找到关于fieldInfo和dataset的详细信息。VMind会根据用户的展示意图,编写SQL语句并对dataset执行查询,查询结果会被储存在函数返回值的dataset属性中;同时,查询结果中的字段可能会发生变化,更新后的字段信息也会被储存在返回结果的fieldInfo属性中。
下面,让我们通过一个示例来看看如何使用dataQuery函数:
import VMind from '@visactor/vmind'
const sourceDataset = [
{
"Product name": "Coke",
"Sales": 2350
},
{
"Product name": "Coke",
"Sales": 1027
},
{
"Product name": "Coke",
"Sales": 1027
},
{
"Product name": "Coke",
"Sales": 1027
},
{
"Product name": "Sprite",
"Sales": 215
},
{
"Product name": "Sprite",
"Sales": 654
},
{
"Product name": "Sprite",
"Sales": 159
},
{
"Product name": "Sprite",
"Sales": 28
},
{
"Product name": "Fanta",
"Sales": 345
},
{
"Product name": "Fanta",
"Sales": 654
},
{
"Product name": "Fanta",
"Sales": 2100
},
{
"Product name": "Fanta",
"Sales": 1679
},
{
"Product name": "Mirinda",
"Sales": 1476
},
{
"Product name": "Mirinda",
"Sales": 830
},
{
"Product name": "Mirinda",
"Sales": 532
},
{
"Product name": "Mirinda",
"Sales": 498
}
]
const sourceFieldInfo = [
{
"fieldName": "Product name",
"type": "string",
"role": "dimension"
},
{
"fieldName": "Sales",
"type": "int",
"role": "measure"
}
]
const userPrompt=`展示各商品销售额`
const vmind = new VMind(options)
//调用dataQuery传入userPrompt,sourceFieldInfo和sourceDataset,执行数据聚合
const { fieldInfo, dataset } = vmind.dataQuery(userPrompt, sourceFieldInfo, sourceDataset);
在这个例子中,dataQuery函数返回的dataset如下:
[
{
"Product name": "Coke",
"total_sales": 5431
},
{
"Product name": "Sprite",
"total_sales": 1056
},
{
"Product name": "Fanta",
"total_sales": 4778
},
{
"Product name": "Mirinda",
"total_sales": 3336
}
]
返回的fieldInfo如下:
[
{
"fieldName": "Product name",
"description": "The name of the product.",
"type": "string",
"role": "dimension"
},
{
"fieldName": "total_sales",
"description": "An aggregated field representing the total sales of each product. It is generated by summing up the 'Sales' values for each product.",
"type": "int",
"role": "measure"
}
]
有了这些信息,我们就可以直接使用fieldInfo和dataset生成图表了。具体的操作步骤,你可以在图表智能生成章节中找到。
📢 注意:dataQuery方法会将userPrompt和fieldInfo传递给大模型用于生成SQL,dataset中的明细数据并不会被传递。
最后,我们将得到如下的柱状图:
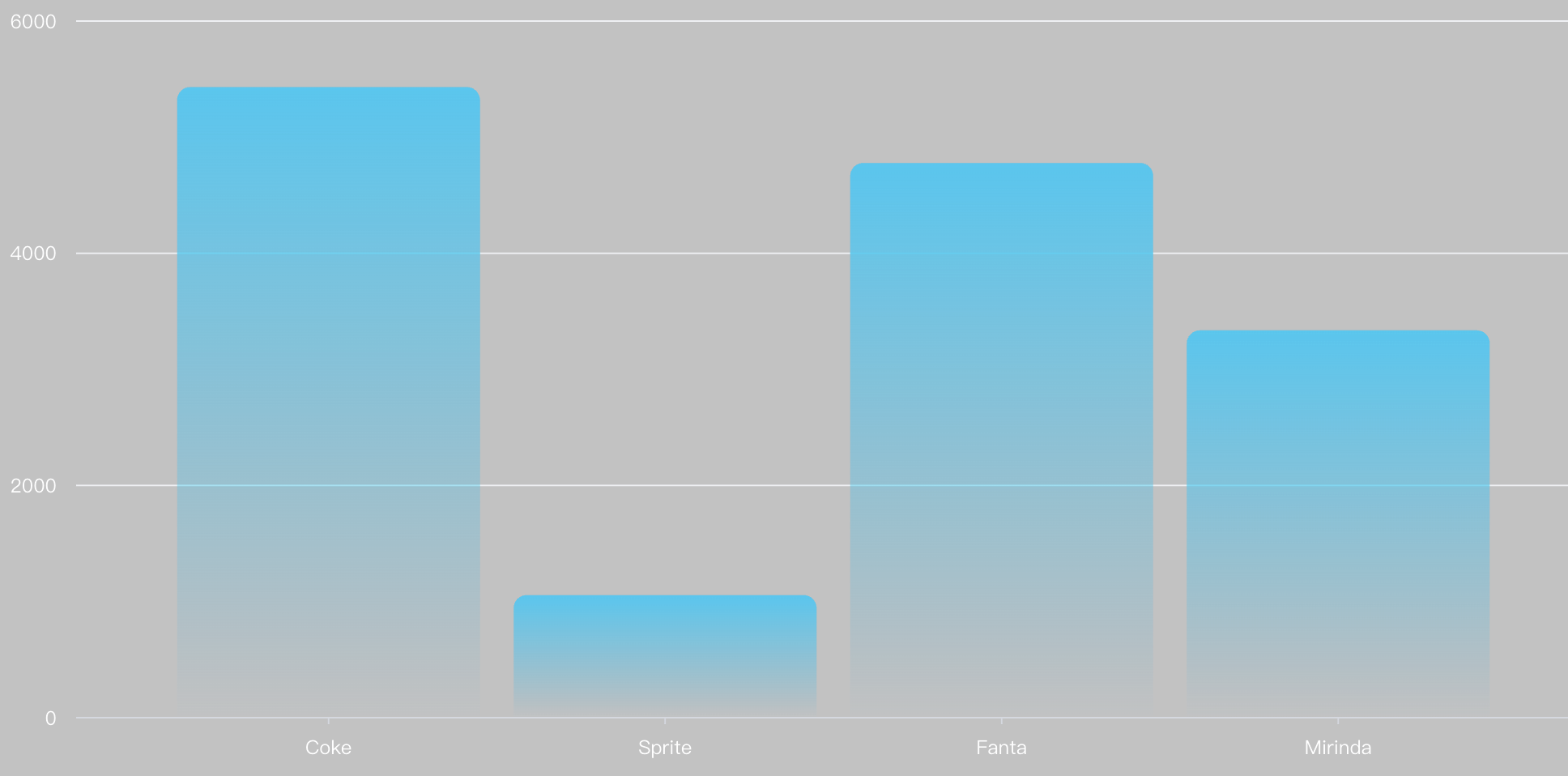
在这个例子中,VMind生成的SQL语句为:
SELECT `Product name`, SUM(`Sales`) AS total_sales FROM dataSource GROUP BY `Product name`
这条SQL语句从sourceDataset中筛选出Produce name和Sales两个字段,按照Produce name进行分组,并对Sales字段进行了求和,生成了新的字段total_sales。VMind将执行这一sql语句,得到聚合后的数据集。
需要注意的是,dataQuery执行过程中,目前支持的SQL关键词有:SELECT, GROUP BY, WHERE, HAVING, ORDER BY, LIMIT。目前支持的聚合函数有:MAX(), MIN(), SUM(), COUNT(), AVG(),但不支持子查询、JOIN、条件语句等复杂的SQL操作。
数据筛选与排序
在这个部分,我们将学习如何使用自然语言来对数据集进行筛选和排序等操作。
首先,让我们看一下下面的数据集(dataset)和字段信息(fieldInfo):
import VMind from '@visactor/vmind'
const sourceDataset = [
{
"商品名称": "可乐",
"region": "south",
"销售额": 2350
},
{
"商品名称": "可乐",
"region": "east",
"销售额": 1027
},
{
"商品名称": "可乐",
"region": "west",
"销售额": 1027
},
{
"商品名称": "可乐",
"region": "north",
"销售额": 1027
},
{
"商品名称": "雪碧",
"region": "south",
"销售额": 215
},
{
"商品名称": "雪碧",
"region": "east",
"销售额": 654
},
{
"商品名称": "雪碧",
"region": "west",
"销售额": 159
},
{
"商品名称": "雪碧",
"region": "north",
"销售额": 28
},
{
"商品名称": "芬达",
"region": "south",
"销售额": 345
},
{
"商品名称": "芬达",
"region": "east",
"销售额": 654
},
{
"商品名称": "芬达",
"region": "west",
"销售额": 2100
},
{
"商品名称": "芬达",
"region": "north",
"销售额": 1679
},
{
"商品名称": "醒目",
"region": "south",
"销售额": 1476
},
{
"商品名称": "醒目",
"region": "east",
"销售额": 830
},
{
"商品名称": "醒目",
"region": "west",
"销售额": 532
},
{
"商品名称": "醒目",
"region": "north",
"销售额": 498
}
]
const sourceFieldInfo = [
{
"fieldName": "商品名称",
"type": "string",
"role": "dimension"
},
{
"fieldName": "region",
"type": "string",
"role": "dimension"
},
{
"fieldName": "销售额",
"type": "int",
"role": "measure"
}
]
假设我们想要展示北方区域销售额排名前三的商品,我们可以这样做:
const userPrompt = `帮我展示北方排名前三的商品销售额`
const vmind = new VMind(options)
// 调用dataQuery方法,传入userPrompt,sourceFieldInfo和sourceDataset,执行数据聚合
const { fieldInfo, dataset } = vmind.dataQuery(userPrompt, sourceFieldInfo, sourceDataset);
在dataQuery方法执行过程中,会生成如下的SQL语句:
SELECT `商品名称`, SUM(`销售额`) AS total_sales FROM dataSource WHERE region = 'north' GROUP BY `商品名称` ORDER BY total_sales DESC LIMIT 3
这个SQL语句将筛选出区域(region)为'north'的数据,然后按照"商品名称"进行分组,并计算每个商品的总销售额,最后按照销售额从高到低排序,并只取销售额最高的前三个商品。
最后,执行图表生成操作,我们就可以得到如下的图表: