
智能洞察
在数据驱动决策的时代,图表作为数据可视化的核心工具,能够直观地呈现复杂的数据关系。然而,单纯依赖人眼观察和分析图表,往往难以快速、全面地挖掘出数据背后隐藏的洞察。
本教程将向你介绍VMind中智能洞察功能,如何通过getInsights快速从图表中获取各种类型的洞察,并提供一些示例。
getInsights
VMind的getInsights函数是一个强大的工具,它可以帮你从图表中获取图表洞察,并产生语义化的解释。这个函数只需要如下两个参数:
- spec: 当前VChart图表的具体spec配置
- options (DataInsightOptions): 洞察相关配置,控制了具体洞察的数量,使用的算法和对应算法的具体配置
在产生智能洞察的过程中,VMind主要做了两件事情,
- 先通过内置的统计学算法,获取当前图表中蕴含的数据洞察;
- 再这些识别出来的洞察传递给大模型;让大模型对这些洞察进行润色和语义化解释,在润色过程中,VMind会将字段信息和洞察类型传递给大模型,并不会把任何数据细节传递给大模型;
其中第二部大模型润色并不是必须的,可以通过options.usePolish对其进行关闭,此时会得到数据洞察和模版化的语义内容。
内置算法
目前VMind内置的算法主要为统计学相关算法,具体如下所示:
- LOF(Local Outlier Factor) 局部异常因子检测算法
- zScore 全局异常点检测
- IQR (Interquartile Range) 四分位全局异常检测算法
- Page-Hinkley Test 时序数据异常检测算法
- Bayesian Inference 转折点检测算法
- Mann-Kendall Test 趋势检测算法
- Pearson Correlation Coefficient / SpearmanCorrelation 相关性检测
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 算法
- Coefficient of Variation 基于变异系数的周期性检测
- 基础的统计指标,例如最大/最小/平均值/占比异常等等
大模型润色
大模型在智能洞察中,只是起到了一个文本润色功能,使得最终的结果有着较强的可读性,是个可选配置。
洞察类型
目前根据已有的内置算法,VMind可以识别出以下9类不同的洞察类型:
- 异常点
- 时序异常点
- 转折点
- 占比贡献巨大点
- 异常区间
- 整体趋势
- 异常趋势
- 相关性
- 基础统计指标
根据不同的洞察结果,用户可以选取不同的标注/高亮方式在图表中进行呈现。
使用案例
下面��是一个使用getInsights的例子:
import VMind from '@visactor/vmind';
const specJson = {
type: 'line',
xField: ['年份'],
yField: ['高考录取率'],
data: [
{
id: 'data',
values: [
{"年份": 1977, "高考录取率": 0.05},
{"年份": 1978, "高考录取率": 0.07},
{"年份": 1979, "高考录取率": 0.06},
{"年份": 1980, "高考录取率": 0.08},
{"年份": 1981, "高考录取率": 0.11},
{"年份": 1982, "高考录取率": 0.17},
{"年份": 1983, "高考录取率": 0.23},
{"年份": 1984, "高考录取率": 0.29},
{"年份": 1985, "高考录取率": 0.96},
{"年份": 1986, "高考录取率": 0.3},
{"年份": 1987, "高考录取率": 0.27},
{"年份": 1988, "高考录取率": 0.25},
{"年份": 1989, "高考录取率": 0.23},
{"年份": 1990, "高考录取率": 0.22},
{"年份": 1991, "高考录取率": 0.21},
{"年份": 1992, "高考录取率": 0.25},
{"年份": 1993, "高考录取率": 0.34},
{"年份": 1994, "高考录取率": 0.36},
{"年份": 1995, "高考录取率": 0.37},
{"年份": 1996, "高考录取率": 0.4},
{"年份": 1997, "高考录取率": 0.36},
{"年份": 1998, "高考录取率": 0.34},
{"年份": 1999, "高考录取率": 0.56},
{"年份": 2000, "高考录取率": 0.59},
{"年份": 2001, "高考录取率": 0.59},
{"年份": 2002, "高考录取率": 0.63},
{"年份": 2003, "高考录取率": 0.62},
{"年份": 2004, "高考录取率": 0.61},
{"年份": 2005, "高考录取率": 0.57},
{"年份": 2006, "高考录取率": 0.57},
{"年份": 2007, "高考录取率": 0.56},
{"年份": 2008, "高考录取率": 0.57},
{"年份": 2009, "高考录取率": 0.62},
{"年份": 2010, "高考录取率": 0.69},
{"年份": 2011, "高考录取率": 0.72},
{"年份": 2012, "高考录取率": 0.75},
{"年份": 2013, "高考录取率": 0.75},
{"年份": 2014, "高考录取率": 0.74},
{"年份": 2015, "高考录取率": 0.74},
{"年份": 2016, "高考录取率": 0.75},
{"年份": 2017, "高考录取率": 0.74},
{"年份": 2018, "高考录取率": 0.81},
{"年份": 2019, "高考录取率": 0.8},
{"年份": 2020, "高考录取率": 0.8},
{"年份": 2021, "高考录取率": 0.93},
{"年份": 2022, "高考录取率": 0.96}
]
}
]
};
const vmind = new VMind(options)
const { insights } = await vmind.getInsights(specJson, {
/** 最多产生 maxNum个洞察内容 */
maxNum: numLimits,
});
最终产生的结果如下:
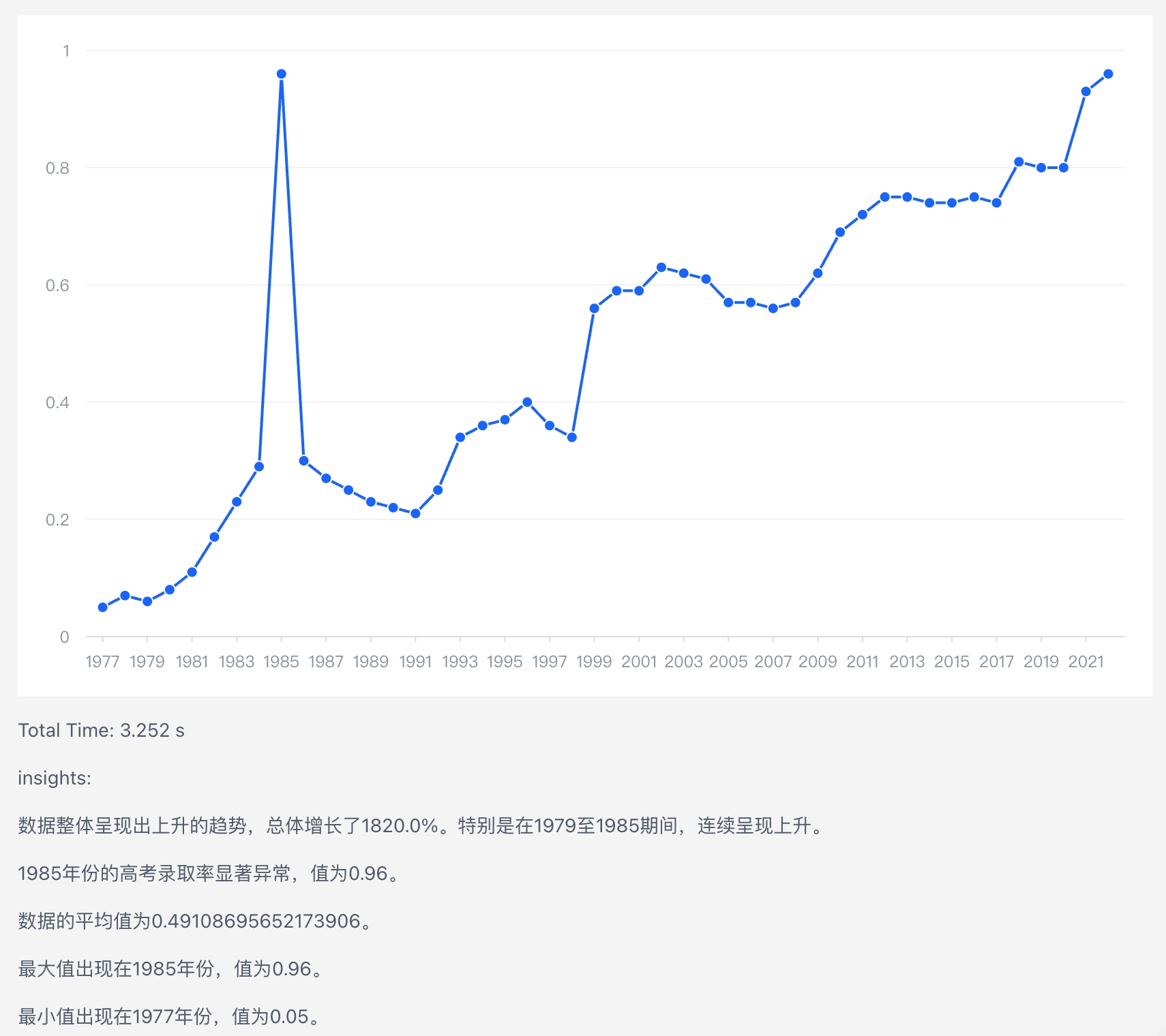
可以准确识别出整体的趋势以及1985年明显异常的高考录取率
返回结构
以整体趋势为例,返回的结构化内容如下:
const outlierInsight = { /** 类型为异常点Insight */ type: 'outlier', /** 具体的异常点数据 */ data: [ { index: 8, dataItem: { 年份: 1985, 高考录取率: 0.96, } } ], /** 数值字段 */ fieldId: '高考录取率', /** 当前异常点数值 */ value: 0.96, /** 洞察置信度得分 */ significant: 1, /** 当前系列名称,因为当前图表没有进行seriesField配置,只包含一个系列,因此为vmind的默认值 */ seriesName: 'vmind_default_series', /** 通过pageHinkley算法检测得到 */ name: 'pageHinkley', /** 具体的文本话含义 */ textContent: { /** 具体的文本模版 */ content: '${b}期间出现显著异常,值为${c}。', /** 模版中的变量解析 */ variables: { b: { isDimValue: true, value: 1985, fieldName: '年份' }, c: { value: 0.96, isMeasure: true, fieldName: '高考录取率' } }, /** 直接将模版变量进行数值替换的结果 */ plainText: '1985期间出现显著异常,值为0.96。' } }
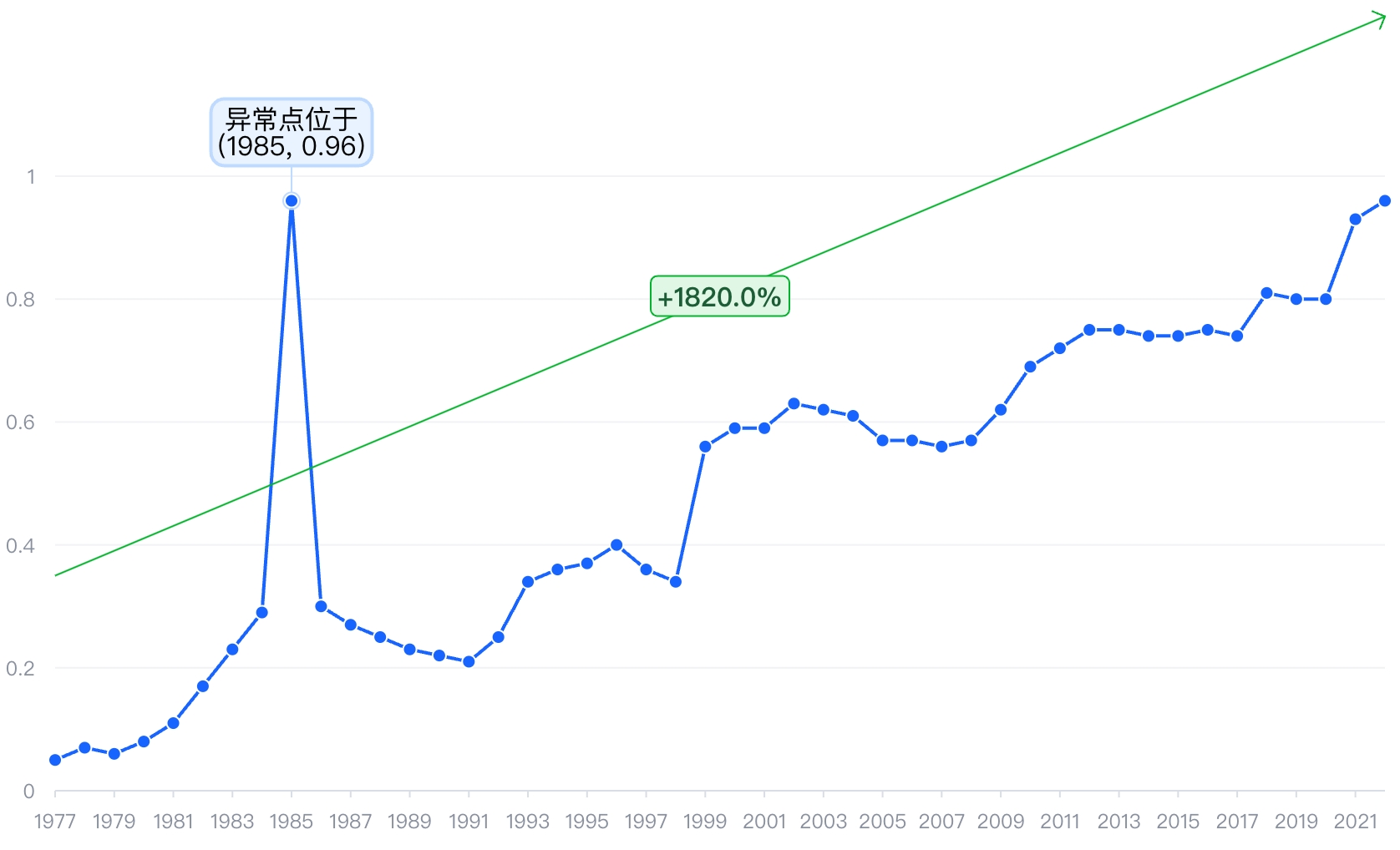
洞察添加
识别出图表洞察后,我们可以借助VChart强大的标注能力,将这些内容添加到图表中,最终效果可以如下图所示:
参数详解
具体参数详解可见:getInsights